
This material is excerpted from Chapter 5 of
The Practice of Programming
by Brian W. Kernighan and Rob Pike
(Addison-Wesley, 1999; ISBN 0-201-61586-X).
Copyright © 1999
Lucent Technologies. All rights reserved.
Oops! Something is badly wrong. My program crashed, or printed nonsense, or seems to be running forever. Now what?
Beginners have a tendency to blame the compiler, the library, or anything other than their own code. Experienced programmers would love to do the same, but they know that, realistically, most problems are their own fault.
Fortunately, most bugs are simple and can be found with simple techniques. Examine the evidence in the erroneous output and try to infer how it could have been produced. Look at any debugging output before the crash; if possible get a stack trace from a debugger. Now you know something of what happened, and where. Pause to reflect. How could that happen? Reason back from the state of the crashed program to determine what could have caused this.
Debugging involves backwards reasoning, like solving murder mysteries. Something impossible occurred, and the only solid information is that it really did occur. So we must think backwards from the result to discover the reasons. Once we have a full explanation, we'll know what to fix and, along the way, likely discover a few other things we hadn't expected.
...
...
...
...
...
``I haven't got a clue. What on earth is going on?'' If you really haven't any idea what could be wrong, life gets tougher.
If the bug can't be made to happen every time, try to understand why not. Does some set of conditions make it happen more often than others? Even if you can't make it happen every time, if you can decrease the time spent waiting for it, you'll find it faster.
If a program provides debugging output, enable it. Simulation programs like the Markov chain program in Chapter 3 should include an option that produces debugging information such as the seed of the random number generator so that output can be reproduced; another option should allow for setting the seed. Many programs include such options and it is a good idea to include similar facilities in your own programs.
Proceed by binary search. Throw away half the input and see if the output is still wrong; if not, go back to the previous state and discard the other half of the input. The same binary search process can be used on the program text itself: eliminate some part of the program that should have no relationship to the bug and see if the bug is still there. An editor with undo is helpful in reducing big test cases and big programs without losing the bug.
Studying the patterns of numbers related to the failure pointed us right at the bug. Elapsed time? A couple of minutes of mystification, five minutes of looking at the data to discover the pattern of missing characters, a minute to search for likely places to fix, and another minute to identify and eliminate the bug. This one would have been hopeless to find with a debugger, since it involved two multiprocess programs, driven by mouse clicks, communicating through a file system.
Display messages in a compact fixed format so they are easy to scan by eye or with programs like the pattern-matching tool grep. (A grep-like program is invaluable for searching text. Chapter 9 includes a simple implementation.) If you're displaying the value of a variable, format it the same way each time. In C and C++, show pointers as hexadecimal numbers with %x or %p; this will help you to see whether two pointers have the same value or are related. Learn to read pointer values and recognize likely and unlikely ones, like zero, negative numbers, odd numbers, and small numbers. Familiarity with the form of addresses will pay off when you're using a debugger, too.
If output is potentially voluminous, it might be sufficient to print single-letter outputs like A, B, ..., as a compact display of where the program went.
/* check: test condition, print and die */
void check(char *s)
{
if (var1 > var2) {
printf("%s: var1 %d var2 %d\n", s, var1, var2);
fflush(stdout); /* make sure all output is out */
abort(); /* signal abnormal termination */
}
}
We wrote
check
to call
abort,
a standard C library function that causes program execution to be terminated abnormally
for analysis with a debugger.
In a different application, you might want
check
to carry on after printing.
Next, add calls to check wherever they might be useful in your code:
check("before suspect");
/* ... suspect code ... */
check("after suspect");
After a bug is fixed, don't throw check away. Leave it in the source, commented out or controlled by a debugging option, so that it can be turned on again when the next difficult problem appears.
For harder problems, check might evolve to do verification and display of data structures. This approach can be generalized to routines that perform ongoing consistency checks of data structures and other information. In a program with intricate data structures, it's a good idea to write these checks before problems happen, as components of the program proper, so they can be turned on when trouble starts. Don't use them only when debugging; leave them installed during all stages of program development. If they're not expensive, it might be wise to leave them always enabled. Large programs like telephone switching systems often devote a significant amount of code to ``audit'' subsystems that monitor information and equipment, and report or even fix problems if they occur.
[Sun Dec 27 16:19:24 1998]
HTTPd: access to /usr/local/httpd/cgi-bin/test.html
failed for m1.cs.bell-labs.com,
reason: client denied by server (CGI non-executable)
from http://m2.cs.bell-labs.com/cgi-bin/test.pl
Be sure to flush I/O buffers so the final log records appear in the log file. Output functions like printf normally buffer their output to print it efficiently; abnormal termination may discard this buffered output. In C, a call to fflush guarantees that all output is written before the program dies; there are analogous flush functions for output streams in C++ and Java. Or, if you can afford the overhead, you can avoid the flushing problem altogether by using unbuffered I/O for log files. The standard functions setbuf and setvbuf control buffering; setbuf(fp, NULL) turns off buffering on the stream fp. The standard error streams stderr, cerr, and System.err are normally unbuffered by default.
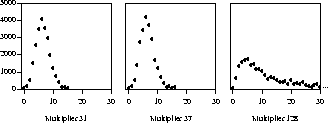
If you don't understand what's happening inside your program, try annotating the data structures with statistics and plotting the result. The following graphs plot, for the C Markov program in Chapter 3, hash chain lengths on the x axis and the number of elements in chains of that length on the y axis. The input data is our standard test, the Book of Psalms (42,685 words, 22,482 prefixes). The first two graphs are for the good hash multipliers of 31 and 37 and the third is for the awful multiplier of 128. In the first two cases, no chain is longer than 15 or 16 elements and most elements are in chains of length 5 or 6. In the third, the distribution is broader, the longest chain has 187 elements, and there are thousands of elements in chains longer than 20.
Write trivial programs to test hypotheses or confirm your understanding of how something works. For instance, is it valid to free a NULL pointer?
int main(void)
{
free(NULL);
return 0;
}
Source code control programs like RCS keep track of versions of code so you can see what has changed and revert to previous versions to restore a known state. Besides indicating what has changed recently, they can also identify sections of code that have a long history of frequent modification; these are often a good place for bugs to lurk.
Bugs that won't stand still are the most difficult to deal with, and usually the problem isn't as obvious as failing hardware. ...
Occasionally hardware itself goes bad. The floating-point flaw in the 1994 Pentium processor that caused certain computations to produce wrong answers was a highly publicized and costly bug in the design of the hardware, but once it had been identified, it was of course reproducible. One of the strangest bugs we ever saw involved a calculator program, long ago on a two-processor system. Sometimes the expression 1/2 would print 0.5 and sometimes it would print some consistent but utterly wrong value like 0.7432; there was no pattern as to whether one got the right answer or the wrong one. The problem was eventually traced to a failure of the floating-point unit in one of the processors. As the calculator program was randomly executed on one processor or the other, answers were either correct or nonsense.
Many years ago we used a machine whose internal temperature could be estimated from the number of low-order bits it got wrong in floating-point calculations. One of the circuit cards was loose; as the machine got warmer, the card tilted further out of its socket, and more data bits were disconnected from the backplane.
What do you do if none of this advice helps?
Buy the book!
Copyright © 1999 Lucent Technologies. All rights reserved.