A third solution employs background threads the create the secondary components during idle periods of the application. A Data Manager is created to construct the secondary components and notify threads that require a component when it is available so that it can proceed. This approach lies between the other two in terms of decreased latency and resource usage. In the example above, the user will typically spend time reading the text in the visible component and the application will be idle waiting for a user action. In this idle period, the other components are created. When the user selects another component, the application waits (blocks) until it is available for display. The component may have already been fully or partially constructed, reducing the latency in display time. At worst, the construction of the component may not have started and the delay between the user action and the response will be the same as the second approach above. The threads that create these components have low priority ensuring that other tasks generated by user actions are handled promptly.
This approach significantly reduces the perceived startup time of an application and also allows useful parts of the application to be displayed "immediately". In one application we developed, there was an improvement in startup time from 14 seconds to 3 seconds. The overall time before all the components were created was increased to approximately 15 seconds, but the application was significantly more useful. The increase in overall startup time is due to the overhead of swapping between the threads and synchronizing access to the variables. On a multi-processor machine, this background construction approach would yield both improved perceived and overall startup time.
ObjectManager.
It is important to recognize that an instance of this
ObjectManger class is not a static object
but acts like a server that continuously listens for and reponds
to requests from its clients. In this sense, it is a thread
that is mostly idle.
The life of the thread can be divided into two stages -
the initial creation of the objects controlled by the Manager
and the processing of requests.
The user passes information to the constructor function
for the Manager in order to create the initial contents
of the Manager's cache. These can be objects to be retrieved
later, or more usefully
expressions describing how to create an object to be stored in the
Manager.
These expressions are processed in a way to be described shortly
and the Manager goes into client-request mode.
It idly sits awaiting a request to retrieve, add or remove an
object that it manages. Removing an object is relatively
straightforward - the object is removed from the Manager's
table.
A request to add an object may provide
a name by which it can be later retrieved
and either the object itself
or an expression that can be used to create the
object. Similarly, retrieving an object can optionally
pass an expression (explicitly or implicitly) which can be used
to construct the object if it is not already in the Manager's
table.
So the API for the Manager class employs methods for the generic
functions get, assign and remove.
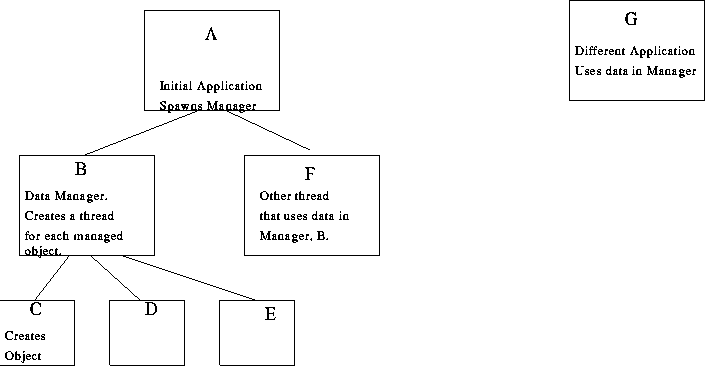
If the manager must create an object (either at initialization or due to a request for an object it has not previously constructed), it should not prohibit other requests from proceeding from other threads accessing data that is already in the manager's table. In order to do this, the object is created in a new thread spawned by the manager. Figure ? shows a thread hierarchy for typical usage of a manager. Each thread passes its return value to the Manager's table and cache's it there. This allows the Manager thread to potentially continue processing all requests while one client is blocked waiting for the result of a given thread. However, this potential depends on the manner in which the code is implemented. There are two possible methods for arranging the necessary computations. We term these remote evaluation and local evaluation. They differ in where the expressions are evaluated that perform the actual retrieval and creation of the objects in the .
Contrast the whole thing with the implementation in Java.
Thread A creates the Manager and intializes it with expressions to create three objects (named "x", "y" and "z"). These objects are created in threads B, C and D. Thread A requests object "x", say, at some point. Thread A spawns thread F for some purpose and supplies it the handle of the Manager (B). Thread F can now make requests for objects in the Manager. In S, multiple applications can be running with access to the same objects, so the manager can service all these, reducing the overhead of creating "expensive" data.
get, assign()
and remove()/rm() methods
and so is transpaarent to the user of the manager's
facilities.)
In this way, the manager does nothing itself
after creating the intializing threads (for each of the objects
it is charged with creating). Each of the threads
making a request of the Manager access the tables itself
and the Manager becomes simply a rendevouz point
for sharing data.
The get() method.
The assign() method.
The remove() method.
One advantage to the remote evaluation setup is that only one thread can modify the tables maintained by the manager and that is the manager thread. Thus, synchronization is simple. This is the positive aspect of the tradeoff between multiplexing and simplicity. The main purpose of the manager is to ensure that the same data object is not created twice.
The methods that implement the remote evaluation idea are simpler than their local evaluation counterparts.
get.datamanager <- function(name, where, how=NULL) {
x = sendTask(substitute(table[[name]]),list(name=name)),where)
or
x = sendTask(substitute(get.datamanager(name),list(name=name)),where)
return(x)
}
There is no synchronization needed in this example since
only the data manager thread is accessing the variables (just table
in this case).
The get() method.
The assign() method.
The remove() method.